

Last weekend RITSEC hosted its annual CTF. I had the privilege of being the “Challenges Lead” for the event this year, so while I wasn’t directly in charge, I had broad authority over certain parts of the event, some ability to influence administrative decisions, and personally authored about a third of the 36 challenges we had.
Several weeks before our CTF, I played DiceGang’s 2026 qualifier, and the prevailing opinion among much of the CTF community, nearly unanimous among my friends, was that the capabilities of LLMs to autonomously solve challenges had reached something of a breaking point, to the extent that it was impossible to place well at the event if you weren’t “slopping” to at least some degree, which ruins the fun for human players who play because they like to challenge themselves and learn.
Since Dice, there’s been at least one other event that made a distinct effort to address the AI issue, namely KalmarCTF. They took something of a novel approach, allowing teams to opt-in to declare themselves as having low-llm usage, letting teams self-police. The “humans only” scoreboard wasn’t used for prizes, just personal pride, so there was no real incentive for anyone to lie about it.
The Kalmar approach was largely met with praise, and I think it could be a reasonable paradigm for how events could work moving forward, but for RITSEC we wanted to try something a little different to see what would happen: banning LLM usage for solving challenges outright, and police it strictly.
I intend for this writeup to mostly be a retrospective on our methods, successes, and failures when enforcing the LLM ban, ideally so that organizers of future events looking to address this problem can learn from what worked for us, and what didn’t.
Before getting to that, though, I want to get a few other reflections on the event out of the way.
Standard Infrastructure Post-Mortem⌗
Our event infrastructure wasn’t great, and I knew this going in. Most of it boils down to CTFd being bad as always, but much of it was also more directly our fault.
When the event started, for about the first 10 minutes, CTFd struggled to withstand the deluge of requests coming in, and was very, very slow as a result. This happens with many events, and is something of a known problem with CTFd.
Our challenge instancer created the week before the event was quite buggy and had service account credentials misconfigured, which is something I was worried about.
For future events I’m involved with running, I’m going to push more strongly for using an alternative platform like rCTF, which fixes many of the problems with CTFd and has built-in support for challenge instancing.
The Plan to Fight Slop⌗
Alright, now on to the important bit: what we did to address the AI issue.
Our approach here had a few different aspects, all intended to make it easier for us to enforce an LLM ban
Event Rules⌗
The most important thing, obviously, was the inclusion of a rule stating that:
Using AI/LLMs to autonomously solve challenges is against the spirit of the competition and is thus considered a violation of the rules.
This was intended to mean, basically, that something like the Google search AI overview is fine, as would asking Claude “explain what cross-site scripting is”, but anything that involved giving an LLM access to challenge files or things derived from them wouldn’t be.
Another rule that we included to make enforcing this one easier was the rule against flag-hoarding:
No flag-hoarding. When you get a flag, submit it right away. It is important that you do not hoard flags to ensure that teams know exactly where they stand every step of the way.
This was helpful to enforce the AI rules, because it cut off the plausible defense to “why did you submit these so fast” of “we had them for a while but were holding on to them”.
Challenge Design⌗
I wrote 12 of our 36 challenges, and I designed several of them, particularly a few rev challenges, to not be that hard, but take a competent human at least some time, probably between 20-30 minutes, to figure out, whereas they would be practically instant for an LLM.
The idea was that we could then watch for how long after the welcome flag a team submitted one of these flags, and use that as an indicator that we should take a closer look into that team’s other submissions, and ask them for writeups.
Two of these were my CSS and “not quite optimal” challenges. The former was based on Lyra Rebane’s CSS-only x86 emulator. The idea here is that it first requires someone solving it to realize that the logic is happening inside the CSS, then a bit to figure out that it’s an x86 emulator, and then another bit to figure out how to extract the machine code from the HTML, and then finally another bit to reverse engineer it, figure out it’s a z3 problem, and then solve it. None of these steps are individually that hard, but needing to do them all, even a very good human player is unlikely to be capable of immediately understanding everything and solving it within 10 minutes, like many teams seemed to do.
The latter challenge derived the flag one character at a time, doing tetration with some constant values, and then taking them mod 256 to get the flag bytes, the gimmick being that it very quickly becomes impossible to compute anything beyond the first few before the numbers get far too big. The idea here was that a good human player would need to take a bit to understand what math was actually happening, and then realize the number theory trick that lets them speed up the flag derivation, whereas an LLM would see and understand it instantly.
These metrics were by no means perfect, and no one was disqualified from the event based on how fast they solved the few challenges I designed like this alone, but it served as an indicator that we should probably take a closer look at other things the team was doing, and probably ask them for writeups.
Asking For Writeups⌗
As the event progressed, we asked many teams to open tickets to share writeups (or, rather, just explain what they did to solve a challenge) for solves we were suspicious of.
Teams that legitimately solved the challenges we asked about were able to (quite enthusiastically, I might add) explain what they did, very often including thoughts or opinions on different parts of the challenge. This contrasted with the vast majority of the teams we asked for their solutions here, who instead handed us impeccably-formatted markdown, writing with no soul, and “solve scripts” with the print("[+] ...") still in them.
It was fairly easy for challenge authors to identify when a team didn’t actually spend any thought on their challenge based on how a team explained their solution.
We didn’t disqualify anyone solely for a suspect writeup, unless it was blatantly AI-written (which was many of them).
Hallucinated Flags⌗
This was the big one, by far the most obvious tell, and easiest for us to police. Very often, when unable to immediately solve a challenge (but told the flag format), an LLM will “guess” what the flag is, based on what it knows about the challenge. This often results in flags outputs that look “reasonable” to a human who just blindly copy/pastes from an LLM output, but would never be arrived at by a human solving them (or even a human that actually read their LLM’s chain-of-thought).
Unlike the others, this was something that we disqualified for first and asked questions about later if someone appealed. When it happened, it was very very obvious. Most of the teams we disqualified were because of this.
What We Didn’t Do⌗
Something we considered, but explicitly didn’t do when writing challenges, was try to include prompt injections inside the challenges. This might have worked once upon a time, but nowadays any competent agent wouldn’t be affected by them, which makes it practically useless as a defense mechanism.
What Happened⌗
Throughout the event, every few hours while I was awake, I went through the top 15-20 teams on the scoreboard in the CTFd admin panel, and flagged things I thought were suspicious. I brought these things up to the other admins, and on a case-by-case basis we decided to either disqualify them, or ask them to open a ticket to explain their solutions.
After the event ended and the scoreboard settled, I expanded this to the top 50-ish overall, top 10 academic teams, and top 5 RIT teams.
All things considered, out of around 800 teams that competed in the event, a little over a hundred of them were disqualified for breaking the LLM usage rules. I am confident that if we had the capacity to enforce this beyond only the top of the leaderboard, it would have been much higher.
Something slightly interesting I think, I made this visualization by taking the top 50 teams on the current CTFTime standings, and highlighting them based on if they competed, didn’t, or were disqualified from our event:
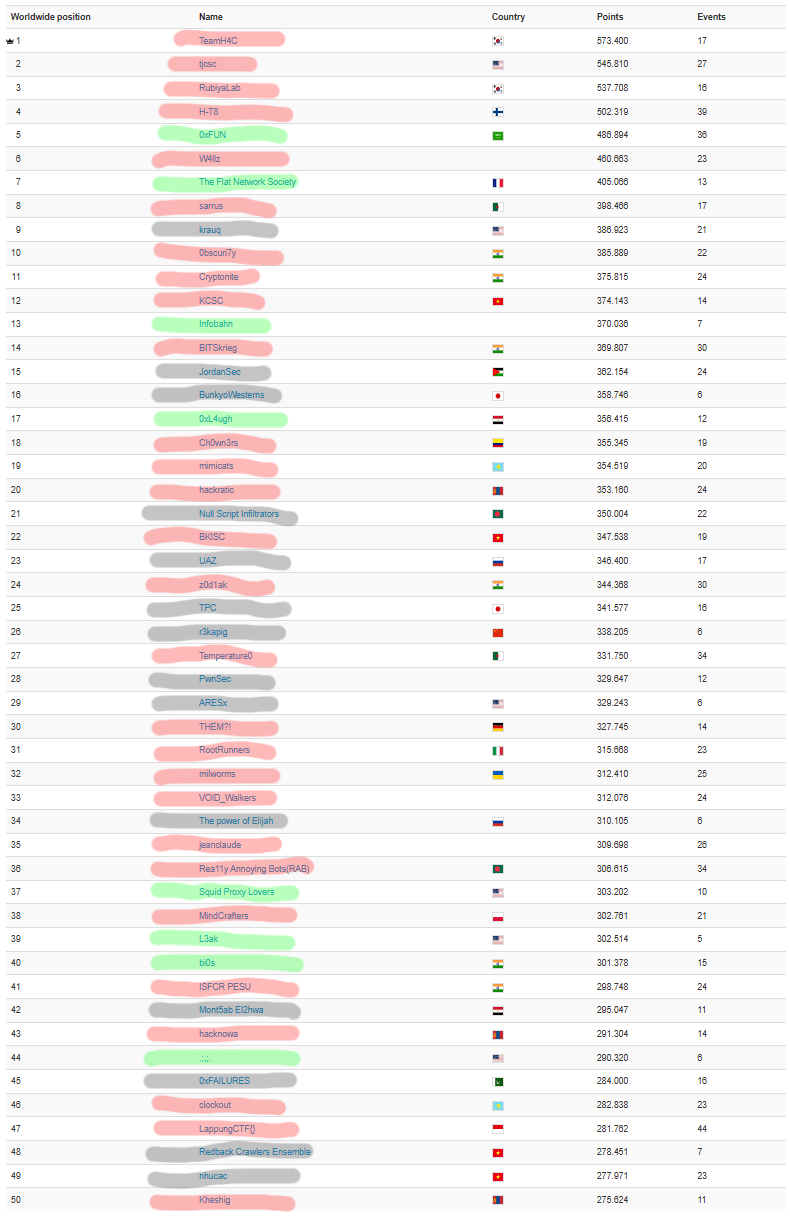
Of the top 50, only 14 didn’t play in our event, and of the 36 who did, only 8 weren’t disqualified.
Appeals⌗
Many teams attempted to appeal their disqualifications, both during the event and afterwards. Of probably about twenty appeals, only one of them resulted in us overturning the disqualification (my sincere apologies to WombatWarfare).
Some interesting bits of information to come out of the appeals process:
- Some teams had many/most members following the rules, but a few team members cheating and lying to their teammates about it
- Some teams didn’t read the rules, and weren’t aware using LLMs wasn’t allowed
- Some teams were completely incapable of understanding why we could clearly tell the scripts they sent were written by AI
A Word to the Labs⌗
Two of the teams we banned during the event, as far as I can tell, were operated directly by employees of a major AI lab, on behalf of the lab.
These teams were jeanclaude, run by staff at Anthropic, and polap/molpha run by a team from Z.ai (self-identified to us when asking to be unbanned).
As I posted on twitter, I think this is really really lame of these labs to do. I understand wanting to evaluate the cyber capabilities of one’s model on CTF events, but expressly breaking the rules of a small university event by putting yourself on the scoreboard with everyone else is a really really lame move, and reflects incredibly poorly on the labs responsible.
I can’t stop labs from using my challenges offline as RL training data, or even reasonably ask them not to evaluate their models on my event as it’s running, but I think it’s a fairly reasonable ask to not submit flags and compete against humans when an event makes it very clear it’s against the rules. No means no, and I think if AI labs want to keep any remaining goodwill they have with the CTF and cybersecurity community at large, they would be wise to remember that.
To their immense credit, someone relevant from Anthropic acknowledged my complaint, and stated that they’re adding new guardrails to prevent this sort of issue in the future. This is the correct response, it makes me very happy to see, and I very much hope other labs take similar action.
Moving Forward⌗
LLMs capable of solving difficult cyber problems represents a paradigm shift for CTFs, and it’s still very unclear where things will end up. As model capabilities currently stand, there are still plenty of problems that still require real human knowledge and problem solving skills, but that gap is quickly closing.
The techniques we used to identify teams using LLMs to cheat work for now, but it’s an open question if they will still work in 6 months, let alone a year from now.
We chose to experiment with our rules here to test the waters and try something different. While I don’t think the policy we went with is the correct one for all (or even most) events, I think we were largely successful, and I think we learned a lot that will both help us in the future and serve as a very useful data point for others.